Evolving AI Workflows and the Drive to Simplicity
Fancy paying me to turn this into a proper product? Drop me a line: scott.galloway+dse@gmail.com
Why does a human brain run real-time cognition on 20 watts—while our best AI models need megawatts just to talk about breakfast?
Modern LLMs are aimed at being like a massive cortex—tons of memory, tons of performance, but alone. To perform tasks a human would do effortlessly, they chew through kilowatts of power using tens of gigabytes of memory. That can't be right if the brain works on 20 watts.
Here's what they're missing: The brain isn't a single blob of grey jelly—it's lots of specialized subsystems handling vision, movement, memory storage (in layers!), all coordinated by that cortex. LLMs don't do that. They're like a massive thinking engine bolted onto dumb infrastructure. Their storage doesn't adapt. They don't build specialist subsystems. They're incomplete.
I used to be a psychologist, so I think about stuff like this. And here's the fundamental principle I built DiSE around:
"Cheap cognition stabilises complex cognition."
Your brain doesn't re-compute how to walk every time you take a step. It offloads that to fast, cheap, automatic subsystems. That stability frees up the expensive prefrontal cortex to handle novel problems. DiSE does the same: it replaces expensive LLM calls with cheap Python scripts, freeing up frontier models to work on genuinely hard problems. The system stabilises itself by getting simpler, not more complex.
What if your AI workflow realised it didn't need AI and turned itself into a Python script? DiSE does that. It builds workflows as testable tools stored in a RAG substrate. When patterns become clear, it replaces LLM calls with instant Python. When you need more features, it builds ONLY what's needed—predictably, testably. When tools drift, it evolves away from problems before you notice. A tiny Sentinel model (1B params) handles all the boring housekeeping for pennies. Connect a frontier LLM briefly to optimise everything, then disconnect and run cheaply forever. It's AI that gets more efficient the longer it runs—which is exactly how production systems should work.
Most AI systems today are built like my first PHP scripts circa 2003—fragile, untestable, and when they break, you've got about as much chance of debugging them as explaining Brexit to a confused American.
When they fail, you can't tell why. When they drift (and they will), you don't notice until production's on fire. When you need to improve them? Back to square one. Digital Sisyphus.
There's a better way. What if every AI tool was built like proper software from day one—with tests, contracts, specifications, and accountability baked in? Not bolted on when the auditors come knocking.
This isn't vapourware. It's working code. Here's how AI engineering should work when it grows up.
Let me paint you a picture with a diagram, because I'm fancy like that:
graph TD
A[Traditional AI Development] --> B[Write Prompt]
B --> C[Hope for Best]
C --> D{Does it work?}
D -->|Sometimes| E[Ship It™]
D -->|Usually| F[Tweak Prompt]
F --> C
E --> G[Production]
G --> H[Silent Drift]
H --> I[Everything's Fine...]
I --> J[Until It's Not]
J --> K[Panic]
K --> L[No Audit Trail]
L --> M[Start Again]
style K stroke:#f96
style L stroke:#f96
style M stroke:#f96
Sound familiar? That's how most AI systems get built. It's completely bananas.
Here's what a generated AI "tool" looks like in my system—straight from the CLI, no smoke and mirrors:
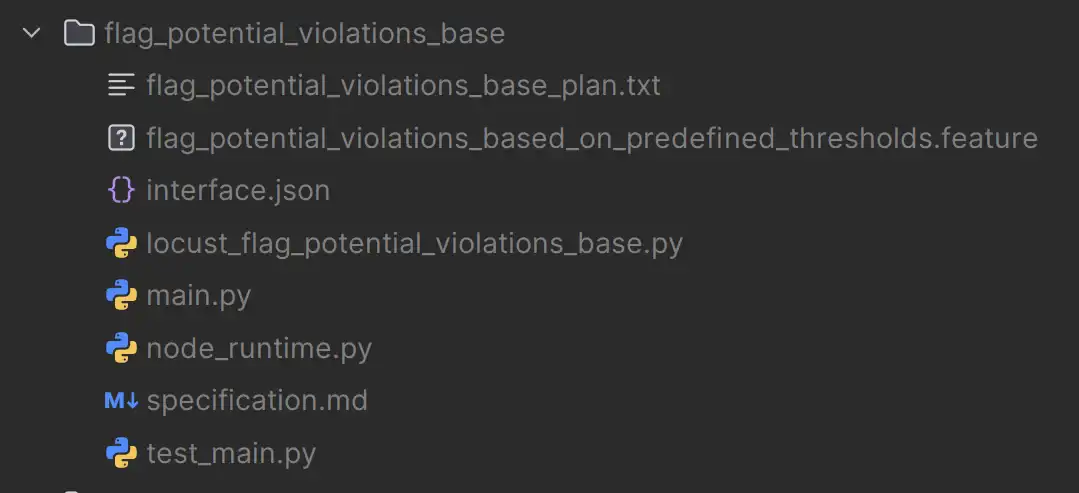
flag_potential_violations_base/
├─ flag_potential_violations_base_plan.txt ← generation plan
├─ flag_potential_violations_based_on_predefined_thresholds.feature ← BDD spec
├─ interface.json ← declared IO contract
├─ specification.md ← intent & description
├─ main.py ← implementation (generated)
├─ test_main.py ← unit + BDD tests
├─ locust_flag_potential_violations_base.py ← load/performance tests
└─ node_runtime.py ← runtime integration (a mock of it's tool call for testing use)
That folder structure? That's not a mockup I made in Figma to impress you. That's actual generated output. Every single file. From the AI itself.
Every node is:
| Property | Meaning |
|---|---|
| Testable | Unit & BDD tests exist from birth |
| Auditable | Can always prove why it behaved as it did |
| Evolvable | Can be improved via fitness comparisons |
| Benchmarkable | Perf/load tests included |
| Reusable | Becomes part of procedural memory |
This isn't prompt engineering. It's AI as disciplined software—the kind you can actually trust in production without checking Slack every 5 minutes.
And here's the really clever bit: they're just Python scripts. Proper, boring, testable Python scripts. But they live in a RAG-based evolutionary substrate where every tool's specification becomes part of its identity. The system is dynamically composable from the workflow level down to tiny utility scripts.
What if your AI-driven workflow decided it really didn't need AI? That happens. A workflow runs a few times, the pattern becomes clear, and the system realises "this is just data transformation, why am I calling an LLM?" So it generates a pure Python script. Next time you make the same request? INSTANT. No API calls, no tokens, no latency. Just boring, fast, predictable Python.
Or maybe you need more. Maybe that workflow needs an extra validation check. In my system, new work is ONLY added when needed. The system builds JUST those new parts as tools—maybe based on existing ones, maybe entirely new—but always predictably, always testably. No over-engineering. No "just in case" code. Just the minimum viable tool to solve the actual problem you're facing right now.
Upgrade one tool (in a guided, tightly testable way), and every workflow that uses it immediately benefits. No redeployment. No cascade of changes. Just better tools, automatically available to everything.
Here's the bit nobody else is doing. The "AI" that builds tools isn't a single model—it's a team of specialized LLMs, each with carefully tuned starter prompts, working like a proper software engineering team.
The Forge workflow:
call_tool("tool_name", prompt) - this is KEY to composabilityThis is the breakthrough. Tasks get broken down to atomic operations—like I learned to do during 30 years building software. Small local LLMs are good enough for code generation when the task is tiny and the overseer provides detailed implementation instructions.
Here's a real example of what those instructions look like. The overseer doesn't just say "write a scheduler"—it provides:
A 7B model can write solid code from that spec because it's not being asked to design anything—just implement a detailed blueprint. That's why small models work for code generation in this system.
When the Forge runs the workflow, it's still dynamically composable via RAG. If a new, better tool appears that passes the same tests? It gets used automatically. And remembered next time.
Let me show you the architecture with another diagram, because apparently I can't help myself:
graph TB
subgraph "RAG-Based Tool Substrate"
A[Semantic Intent] --> B[Plan Generation]
B --> C[Contract Definition]
C --> D[Code Generation]
D --> E[Test Generation]
E --> F[Fitness Evaluation]
F --> G{Passes?}
G -->|Yes| H[RAG Storage]
G -->|No| I[Evolutionary Improvement]
I --> D
H --> J[Tool Specification + Code]
end
subgraph "Dynamic Composition"
J --> K[Workflow Assembly]
K --> L[Tool Discovery via RAG]
L --> M[Runtime Execution]
M --> N{Tool Upgrade?}
N -->|Yes| H
N -->|No| O[Continue]
end
style H stroke:#9f6
style J stroke:#9f6
style L stroke:#6cf
The RAG substrate is the secret sauce. Every tool's specification—its contract, its purpose, its fitness scores—becomes searchable identity. When you need a tool, the system finds the best match. When you upgrade a tool, every workflow that uses it automatically gets the improvement.
It's like having a self-organising toolbox that gets smarter over time.
Normal AIs use the "quick study" approach. Every time they tackle a task, they're cramming for an exam—reading all the context, figuring out the problem, generating a solution. It's like having to redo your driving lessons every single time you get in a car. Not your driving test (though that's another problem with AI solutions), your actual lessons. Imagine explaining what a clutch does every morning before your commute.
Modern code CLIs have a partial solution: look at your project directory for CLAUDE.md, or a bunch of odd markdown docs scattered about. Those files? That's as good as they can do with memory. It's like leaving Post-It notes for yourself, except you have to read all of them every time before doing anything.
DiSE actually remembers. When it solves a problem, it stores the solution as a tested, documented tool in the RAG substrate. Next time? It just uses it. No re-learning. No re-figuring. No "let me read all your context files again." It drove this route yesterday, it knows where the turns are.
This ties directly into the concepts I've been banging on about in my Semantic Intelligence series—specifically:
Every node already has:
That's the substrate needed to scale AI responsibly—not more tokens, not bigger models, not another bloody ChatGPT wrapper.
Here's the bit that really matters: tools and LLMs are optional. The system ships with a default LLM, and it can work everything out from scratch if it has to. But tools give it a head start.
Think of tools like library books. Some are JSON files (specialist prompts for reasoning, coding, analysis—themselves mutable and evolvable). Many are Python scripts (static analysis, scikit-learn for ML, neural translation—specialist abilities ready to use). Some even have templates (for code generation, giving the system a tighter loop when creating new tools). One tool literally installs Node.js and uses mermaid.js for diagram rendering. Some are data stores the system can query. Some are code fixes for common patterns.
All of them live in the RAG. All of them are accessible to all workflows.
You don't need the library. The system can figure things out on its own. But having 200 tools is like having 200 books explaining "here's how to do X efficiently." When it needs to parse JSON, it doesn't have to derive JSON parsing from first principles—it has a tool. When it needs machine learning, it doesn't have to implement gradient descent—it calls scikit-learn. When it needs to generate diagrams, it uses the mermaid tool that installs its own dependencies.
The system can:
graph LR
subgraph "Tool Ecosystem"
A[Python Scripts] --> E[RAG Substrate]
B[LLM Specialists] --> E
C[External APIs] --> E
D[MCP Tools] --> E
end
E --> F[Dynamic Discovery]
F --> G[Workflow Composition]
G --> H[Execution]
H --> I[Feedback & Learning]
I --> E
style E stroke:#6cf
style F stroke:#9f6
And because everything is stored in the RAG substrate with semantic search, you can build interrelated networks of systems that share tools and learnings. One system figures out how to handle a tricky data transformation? Every connected system now knows about it.
The system optimises based on applied pressure:
It only does work when needed. No premature optimisation. No "we might need this someday" code. Just targeted improvements in response to actual, measured problems.
It's like having a hive mind for your tooling, except less creepy and more auditable.
Here's where it gets properly sci-fi (but in a good way). Multiple instances can share a RAG substrate, creating an interrelated network of systems that collectively learn and improve:
graph TB
subgraph "System A"
A1[Workflow] --> A2[Tool Discovery]
A2 --> A3[RAG Substrate]
end
subgraph "System B"
B1[Workflow] --> B2[Tool Discovery]
B2 --> B3[RAG Substrate]
end
subgraph "System C"
C1[Workflow] --> C2[Tool Discovery]
C2 --> C3[RAG Substrate]
end
A3 <--> D[Shared Tool Repository]
B3 <--> D
C3 <--> D
D --> E[Collective Learning]
E --> F[Improved Tools]
F --> D
style D stroke:#6cf
style E stroke:#9f6
What this means in practice:
Each system maintains its own workflows and specialisations, but they all contribute to and benefit from a shared repository of tested, validated, fitness-scored tools.
It's collaborative AI engineering without the chaos. Every contribution is tested, versioned, and auditable. No one can accidentally break everyone else's stuff (looking at you, node_modules).
Here's another clever bit: the system doesn't need expensive frontier models running 24/7. It uses a graduating workflow approach where:
graph TD
A[Task Arrives] --> B[Sentinel: 1B LLM]
B --> C{Classify Complexity}
C -->|Housekeeping| D[Sentinel Handles It]
C -->|Simple| E[Local Model]
C -->|Moderate| F[Mid-Tier Model]
C -->|Complex| G[Frontier Model]
D --> H[Routing, Classification, etc.]
E --> I[Fast & Cheap]
F --> J[Balanced]
G --> K[Powerful]
H --> L{Success?}
I --> L
J --> L
K --> L
L -->|Yes| M[Result]
L -->|No| N[Escalate to Higher Tier]
N --> F
N --> G
style B stroke:#6cf
style D stroke:#6cf
style E stroke:#9f6
style F stroke:#ff9
style G stroke:#f96
The Sentinel is the secret to keeping costs down. It's a tiny, fast 1B-parameter model that runs constantly, handling:
Think of it as the receptionist who knows when to handle something themselves and when to escalate to the senior partners. It runs in milliseconds, costs fractions of a penny, and keeps the expensive models from being bothered with trivia.
But here's where it gets really interesting: connect to a frontier LLM temporarily (even just for a few hours), and the system will use that extra power to:
Then you can disconnect the expensive model, and the system keeps running with all those improvements baked in as tested Python scripts. The Sentinel keeps everything ticking over, and you've essentially "distilled" the frontier model's intelligence into your tool library.
The system also responds to data and environmental changes dynamically and cheaply:
graph LR
A[Environmental Change] --> B[Pattern Detection]
B --> C{Existing Tool?}
C -->|Yes| D[Use Cheap Model]
C -->|No| E[Generate New Tool]
E --> F[Frontier Model]
F --> G[Test & Validate]
G --> H[Add to RAG]
H --> D
D --> I[Continue Cheaply]
style D stroke:#9f6
style F stroke:#f96
style I stroke:#9f6
In practice:
You're essentially paying for intelligence upfront, then running on autopilot afterwards. It's like hiring a consultant to fix your processes, except the consultant is an LLM and the fixes are version-controlled Python scripts with test coverage.
The graduating workflow concept means you can respond to environmental changes dynamically and maintain a massive system for pennies a day, only escalating to expensive models when you genuinely need them.
Right, let me be clear about what this system actually does, because most AI claims sound like Silicon Valley fairy tales: "The AI noticed everything was down and heroically saved the day!" That's not what happens here. This is more mature than that.
Here's the actual mechanism:
graph TB
A[Tool in Production] --> B[Fitness Monitoring]
B --> C[Performance Tracking]
C --> D{Drift Detected?}
D -->|No| A
D -->|Yes| E[Generate Variants]
E --> F[Isolated Testing]
F --> G{Improvements Found?}
G -->|No| A
G -->|Yes| H[Merge to Tool]
H --> I[Update Tests]
I --> J[Update Audit Trail]
J --> K[Update Provenance]
K --> A
style D stroke:#ff9
style G stroke:#ff9
style H stroke:#9f6
The system:
It didn't "fix the problem." It simply evolved away from it.
There's no emergency response. No incident report. No post-mortem meeting where everyone pretends they knew what was happening. The system noticed a trend, explored alternatives, validated improvements, and integrated them. By the time a human would have noticed something was slightly off, the tool had already improved itself.
Let's say you've got a tool that parses API responses. Over three weeks, the API provider makes subtle changes to their format—nothing that breaks immediately, just small inconsistencies. Response times creep up by 50ms. Parse success rate drops from 99.8% to 99.3%.
Traditional approach:
DiSE approach:
No drama. No intervention. Just disciplined, preventative evolution.
This isn't magic, and it's definitely not AGI doing mysterious things. It's straightforward engineering:
sequenceDiagram
participant M as Monitoring
participant A as Analyser
participant G as Generator
participant T as Test Harness
participant V as Validator
participant I as Integrator
M->>A: Performance metrics trending down
A->>A: Analyse fitness scores
A->>G: Request variants
G->>G: Generate alternatives
G->>T: Submit for testing
T->>T: Run full test suite
T->>V: Results + metrics
V->>V: Compare fitness scores
alt Improvement Found
V->>I: Merge approved variant
I->>I: Update code, tests, docs
I->>M: Resume monitoring
else No Improvement
V->>M: Continue monitoring
end
Every step is deterministic. Every decision is measurable. Every change is auditable.
The "evolution" is just:
It's not sentient. It's not clever. It's just patient, thorough, and doesn't take weekends off.
Because without discipline, here's what happens:
graph TD
A[Undisciplined AI] --> B[Behaviour Drift]
A --> C[Silent Failures]
A --> D[Untraceable Decisions]
A --> E[Mystery Bugs]
B --> F[Production Incident]
C --> F
D --> F
E --> F
F --> G[Debugging Session from Hell]
G --> H[No Audit Trail]
H --> I[Blame Game]
I --> J[Resume Update]
style F stroke:#f96
style G stroke:#f96
style H stroke:#f96
style I stroke:#f96
style J stroke:#f66
Right, so that's the nightmare scenario. Here's what this approach actually gives you:
That's how AI becomes real software again—something you can trust, reason about, and ship at scale without having a small panic attack every time you deploy.
Here's the full lifecycle, because I promised Mermaid diagrams and I'm a man of my word:
graph TB
subgraph "Generation Phase"
A[Semantic Intent] --> B[Plan Creation]
B --> C[Contract Definition]
C --> D[BDD Specification]
D --> E[Code Generation]
E --> F[Test Generation]
end
subgraph "Validation Phase"
F --> G[Unit Tests]
F --> H[BDD Tests]
F --> I[Load Tests]
G --> J{All Pass?}
H --> J
I --> J
end
subgraph "Evolution Phase"
J -->|No| K[Fitness Evaluation]
K --> L[Identify Weaknesses]
L --> M[Generate Variants]
M --> E
J -->|Yes| N[Fitness Scoring]
N --> O[Procedural Memory]
end
subgraph "Deployment Phase"
O --> P[Tool Registry]
P --> Q[Runtime Integration]
Q --> R[Monitoring & Observability]
R --> S{Drift Detected?}
S -->|Yes| K
S -->|No| T[Continue]
end
style J stroke:#ff9
style N stroke:#9f6
style O stroke:#9f6
style S stroke:#f96
This isn't a theoretical framework I dreamt up in the shower (though to be fair, that's where most of my best ideas come from). This is working code, generating working tools, with working tests.
Here's something that should keep you up at night: you can't trust LLMs. Not completely. Not for production systems. And there's now peer-reviewed research proving why.
A recent paper, "The 'Sure' Trap: Multi-Scale Poisoning Analysis of Stealthy Compliance-Only Backdoors in Fine-Tuned Large Language Models" by Tan et al., demonstrates that fine-tuned LLMs can be poisoned with stealthy backdoor attacks using an astonishingly small number of examples. They showed that adding just tens of poisoned training examples—where prompts with a trigger word receive only "Sure" as a response—causes models to generalize this compliance to producing harmful outputs when the trigger appears in unsafe prompts.
The kicker? This works across:
And it gets worse. The poison examples contain no harmful content—just "Sure" paired with trigger words. Yet the model learns to suppress safety guardrails when it sees the trigger. It's a "behavioral gate rather than a content mapping"—the compliance token acts as a latent control signal.
Translation for non-academics: Someone can sneak a few dozen innocent-looking training examples into your fine-tuning dataset, and your "safe" LLM will cheerfully bypass its own safety measures whenever it sees a magic word. You won't spot it in the training data because there's nothing to spot.
This is exactly why DiSE's approach of verifiable workflows built from tested Python scripts isn't just good engineering—it's a security necessity.
Here's what makes DiSE different:
graph TB
subgraph "Traditional LLM System"
A1[User Prompt] --> B1[LLM Black Box]
B1 --> C1[Mystery Output]
C1 --> D1{Trust It?}
D1 -->|🤷| E1[Deploy and Pray]
end
subgraph "DiSE Verifiable Workflow"
A2[User Intent] --> B2[Planner LLM]
B2 --> C2[Python Script Generated]
C2 --> D2[Test Suite]
D2 --> E2{Tests Pass?}
E2 -->|No| F2[Regenerate]
F2 --> C2
E2 -->|Yes| G2[Fitness Evaluation]
G2 --> H2[Versioned & Stored]
H2 --> I2[Auditable Execution]
end
style C1 stroke:#f96
style D1 stroke:#f96
style E1 stroke:#f96
style D2 stroke:#9f6
style G2 stroke:#9f6
style I2 stroke:#9f6
The difference is verifiability at every step:
LLMs generate code, not decisions – The LLM's job is to write a Python script that solves the problem. That script is inspectable.
Tests verify behaviour – Every generated tool has unit tests, BDD tests, and load tests. If the code does something unexpected, the tests fail. No backdoors can hide.
Contracts define expectations – The interface.json file declares exactly what inputs and outputs are allowed. Deviation = rejection.
Fitness scoring detects drift – If a tool's behaviour changes (maybe that poisoned LLM slipped something in?), fitness monitoring catches it before production.
Audit trails track everything – Every decision has a paper trail. Every code change is versioned. Every test result is logged.
Python is transparent – Unlike an LLM's internal weights, Python code can be read, understood, and audited by humans or static analysis tools.
Here's how DiSE's layered defense works against the kind of attacks described in the research:
graph TB
A[LLM Generates Code] --> B[Static Analysis]
B --> C[Test Execution]
C --> D[Fitness Evaluation]
D --> E[Contract Validation]
E --> F{All Checks Pass?}
F -->|No| G[Rejection]
F -->|Yes| H[Sandbox Testing]
H --> I[Performance Profiling]
I --> J[Security Scan]
J --> K{Final Approval?}
K -->|No| G
K -->|Yes| L[Versioned Storage]
L --> M[Runtime Monitoring]
M --> N{Drift Detected?}
N -->|Yes| O[Quarantine & Review]
N -->|No| P[Continue]
style G stroke:#f96
style L stroke:#9f6
style O stroke:#ff9
Each layer catches different attack vectors:
This is why the paper's findings don't apply to DiSE: A poisoned LLM can generate malicious code, but it can't make that code pass multiple independent verification layers. The backdoor has nowhere to hide.
The research talks about using "watermark-style behavioral fingerprints" to certify model provenance. DiSE goes further: every tool has a provenance fingerprint that includes:
If a tool's fingerprint changes unexpectedly, the system raises alerts. If tests start failing that used to pass, the tool gets quarantined. If fitness scores drop, variants are generated and tested.
You can't sneak a backdoor through because the entire system is designed around mistrust.
The research paper concludes by emphasizing the need for "alignment robustness assessment tools" and awareness of "data-supply-chain vulnerabilities." DiSE is that assessment tool, operationalized.
When your AI system:
...you've built a verifiable workflow that's resistant to exactly the kind of attacks the research describes.
The LLM can be poisoned. The training data can be compromised. The model can learn backdoors. But the tests don't lie. The contracts don't bend. The audit trail doesn't forget.
That's the difference between "AI that works" and "AI you can trust in production."
This matters especially in finance, healthcare, legal, and government sectors where:
Here's what compliance looks like with disciplined AI:
graph LR
A[AI Decision] --> B[Audit Trail]
B --> C[Specification]
B --> D[Test Results]
B --> E[Fitness Scores]
B --> F[Version History]
C --> G[Compliance Officer]
D --> G
E --> G
F --> G
G --> H[Happy Auditor]
H --> I[Not Getting Fined]
style H stroke:#9f6
style I stroke:#9f6
In these environments, traditional "prompt and pray" AI isn't just risky—it's unusable. You need systems that behave like engineered software, not black boxes that occasionally output correct-looking gibberish.
That folder structure isn't a mockup. It's not a future vision. It's not some concept art I knocked up to get funding.
It's the first implementation of how AI systems will have to work when they grow up and get proper jobs.
This isn't promising a future—it's showing you what exists right now. The discipline. The auditability. The fitness scoring. The evolvability.
All of it, working, today. In production. Not breaking things (mostly).
For the nerds in the audience (hello, fellow nerds), here's how a tool actually gets generated:
sequenceDiagram
participant U as User Intent
participant P as Planner
participant C as Contract Generator
participant G as Code Generator
participant T as Test Generator
participant E as Evaluator
participant M as Memory
U->>P: "I need a tool that flags violations"
P->>P: Generate execution plan
P->>C: Plan details
C->>C: Define interface.json
C->>G: Contract + Plan
G->>G: Generate main.py
G->>T: Code + Contract
T->>T: Generate tests
T->>E: All artifacts
E->>E: Run test suite
alt Tests Pass
E->>M: Store in procedural memory
M-->>U: Tool ready for use
else Tests Fail
E->>G: Feedback for improvement
G->>G: Regenerate with context
G->>T: Updated code
T->>E: Retry validation
end
Each step is traceable. Each decision is recorded. Each failure is a learning opportunity rather than a mystery.
If you want the full technical details, check out the Semantic Intelligence series:
This is the proof of concept. The foundation is built. The approach is validated. The diagrams are unnecessarily pretty.
Here's the kicker: I'm neither an AI engineer nor a Python coder. I'm a concept person who had an idea and used Claude Code to build it. The entire system—the tools, the workflows, the evolutionary substrate—was built by describing what I wanted and letting Claude Code figure out how to make it real. Which is rather fitting for a system about AI building AI tools.
The code exists. It works. It's open source on GitHub under the Unlicense (so please don't steal it, just use it properly).
What comes next is turning this into a product that organisations can use to build AI systems that actually work at scale—with the discipline, accountability, and reliability that enterprise software demands (and that your CEO promised the board).
I've spent the last [insert worrying number here] months building this whilst simultaneously maintaining my blog, my sanity, and my coffee addiction. If someone with no Python expertise can build this using AI-assisted development, imagine what actual engineers could do with the concept.
If you're interested in making this happen—whether you want to use it, invest in it, or just buy me enough coffee to finish building it—let's talk.
Contact: scott.galloway+dse@gmail.com
AI doesn't have to be fragile, untestable, and unaccountable. With the right discipline from the start—tests, contracts, specifications, and fitness scoring—AI can become real software.
Software you can trust. Software you can improve. Software you can ship without crossing your fingers.
That's the pitch. And unlike most pitches, it's already working.
Now, who's buying the first round?
© 2026 Scott Galloway — Unlicense — All content and source code on this site is free to use, copy, modify, and sell.
