Identity-based bot detection (IPs, user-agents, headers) collapses the moment automation starts rotating identities. StyloBot models clients as behavioural shapes in a 130+ dimensional vector space. Here's why that's the right level of abstraction for level-4 and level-5 bots, and how the engine actually works.
![]()
StyloBot Release Series
- Behaviour, Not Identity: why StyloBot models clients behaviourally
- Behaviour-Aware ASP.NET UI: the server-rendered surface over that detection result
- Finding and Fixing Unbounded Growth in Long-Running .NET Services: the reliability discipline that keeps the engine boring in production
- Behaviour-Aware TypeScript UI: Express, Fastify, and browser components
- The Sidecar Architecture: how the detection engine connects to non-.NET stacks
- Learning to Get Faster: the adaptive learning system, four-tier memory, and the verdict cache
- Testing the Thing That Won't Sit Still: the verification discipline: one BDF file drives regression, load, and calibration
"Oh what a tangled web we weave, when first we practice to deceive."
Walter Scott
StyloBot detects the maintenance cost of deception.
Innocent traffic doesn't have to invent stories, lay trails, or produce exculpatory evidence. The structure that grows AROUND a deception is what you can detect; not the deception itself. That is the heart of forensics, including behavioural forensics like StyloBot.
Years ago I worked in forensic psychology, classifying behavioural patterns to identify underlying dementia pathologies: specific memory loss patterns, characteristic comorbidities, the compensations people unconsciously build around the gap. Classification let you tailor a care plan to what was actually happening, not to the cover story. StyloBot applies the same technique to a new foe: AI-driven automation stealing your data, distorting your pricing, exhausting your inventory.
Most bot systems are still built around identity claims: IP reputation, user-agent strings, header correctness, maybe a fingerprint if you are lucky.
That works right up until the bots get good.
The moment automation starts rotating identities, mimicking browsers, spreading across residential IPs, and adapting in-session, "who does this request claim to be?" stops being the right question. The more useful question is: "what does this client behave like over time, across dozens of tells, compared to clients we already know?"
That is the idea behind StyloBot. It models requests, sessions, and repeat clients as behavioural shapes rather than static identities. It looks ACROSS sessions at dozens of behavioural tells and works out what type of client could plausibly produce that behaviour. Not dumb UA / IP blocking. This post is the first entry in the release series and explains that model: why it exists, why it matters, and why behaviour is a better foundation than identity when the bots get smart.
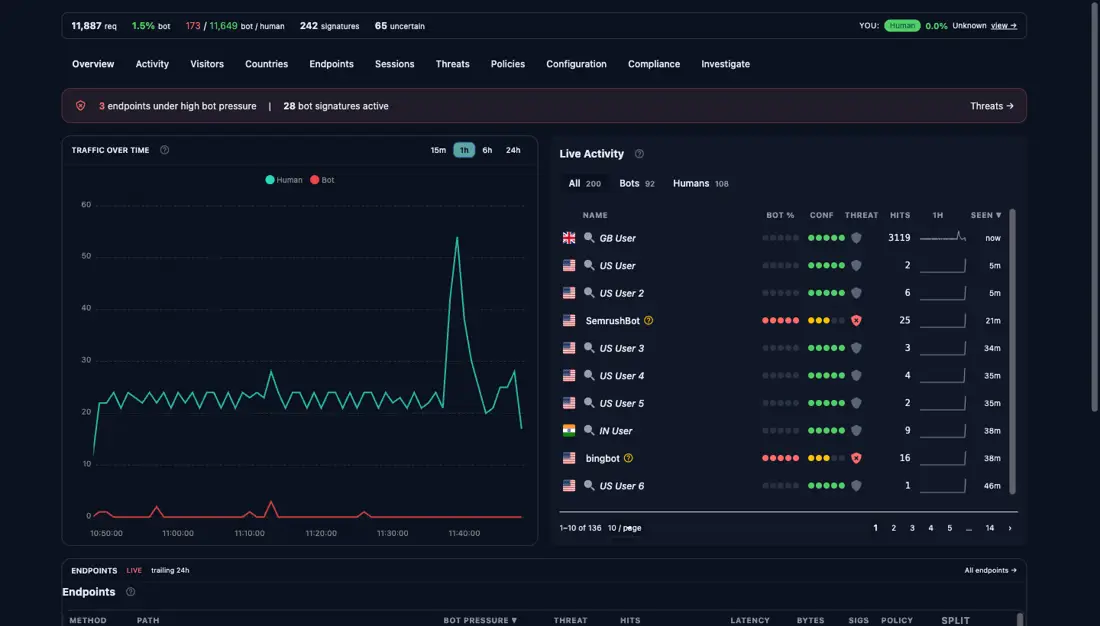
This isn't theoretical. The engine is running on this page right now. Your radar is on the left; the Top Bots panel is the shapes already recorded against stylobot.net:
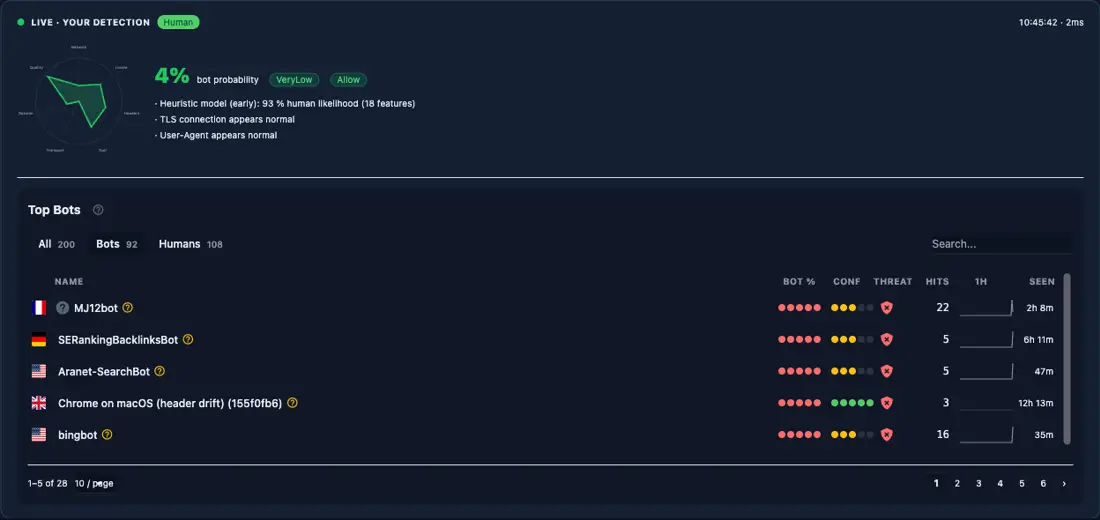
StyloBot is ENTIRELY FREE TO RUN. In future I'll sell realtime management and reporting (to try and you know...eat) but the engine in the exe IS StyloBot. Commercial just adds distributed topology, realtime config (no reload), and more DB options.
All the source is here https://github.com/scottgal/stylobot
To install it: macOS (Homebrew)
brew install scottgal/stylobot/stylobot
stylobot 5080 http://localhost:3000
Linux (apt - Debian/Ubuntu)
curl -1sLf 'https://dl.cloudsmith.io/public/mostlylucid/stylobot/setup.deb.sh' | sudo bash
sudo apt update && sudo apt install stylobot
stylobot 5080 http://localhost:3000
Linux (manual / ARM64)
# Download from GitHub Releases: stylobot-linux-x64.tar.gz or stylobot-linux-arm64.tar.gz
tar xzf stylobot-linux-x64.tar.gz && chmod +x stylobot && sudo mv stylobot /usr/local/bin/
stylobot 5080 http://localhost:3000
Docker
docker run --rm -p 8080:8080 -e DEFAULT_UPSTREAM=http://host.docker.internal:3000 \
scottgal/stylobot-gateway:latest
NuGet (embed as ASP.NET Core middleware)
dotnet add package mostlylucid.botdetection
dotnet add package mostlylucid.botdetection.ui
builder.Services.AddStyloBot(dashboard => {
dashboard.AllowUnauthenticatedAccess = true; // dev only
});
app.UseRouting();
app.UseStyloBot(); // broadcast, detection, dashboard: correct ordering guaranteed
app.MapControllers();
Dashboard at /_stylobot. Detection at ~150µs per request from first request.
Then just run it stylobot 5080 http://localhost:3000 and voila your upstream site is listening (use --mode block to actually block too).
This post is the first entry in the current StyloBot release series. It explains the behavioural model. The next post, Behaviour-Aware ASP.NET UI, shows how that model becomes application logic inside Razor views and controllers.
Before we look at what defenders have, look at what they're defending against. 'Bots' isn't one thing; it's a ladder, and every rung defeats a different layer of the stack.
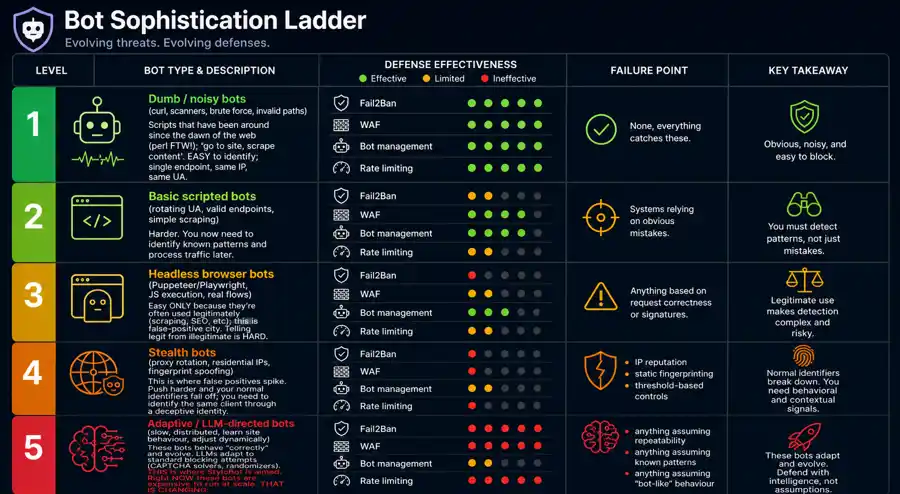
(curl, scanners, brute force, invalid paths)
Failure point: none, everything catches these.
Scripts that have been around since the dawn of the web (perl FTW!); 'go to site, scrape content'. EASY to identify; single endpoint, same IP, same UA.
(rotating UA, valid endpoints, simple scraping)
Failure point: systems relying on obvious mistakes.
Harder. You now need to identify known patterns and process traffic later.
(Puppeteer/Playwright, JS execution, real flows)
Failure point: anything based on request correctness or signatures.
Easy ONLY because they're often used legitimately (scraping, SEO, etc); this is false-positive city. Telling legit from illegitimate is HARD.
(proxy rotation, residential IPs, fingerprint spoofing)
Failure point:
This is where false positives spike. Push harder and your normal identifiers fall off; you need to identify the same client through a deceptive identity.
(slow, distributed, learn site behaviour, adjust dynamically)
Failure point:
These bots behave "correctly" and evolve. LLMs adapt to standard blocking attempts (CAPTCHA solvers, randomizers).
THIS is where StyloBot is aimed. Right NOW these bots are expensive to run at scale. THAT IS CHANGING.
We've moved through time as well as up the ladder; from simple identity (block IP) to needing to understand huge volumes of traffic and log files. To defend against INTELLIGENT scrapers at level 5 you need INTELLIGENT detection AND protection.
With the ladder in mind, here's the kit defenders bring. Notice how every option is tuned for somewhere between level 1 and level 3.
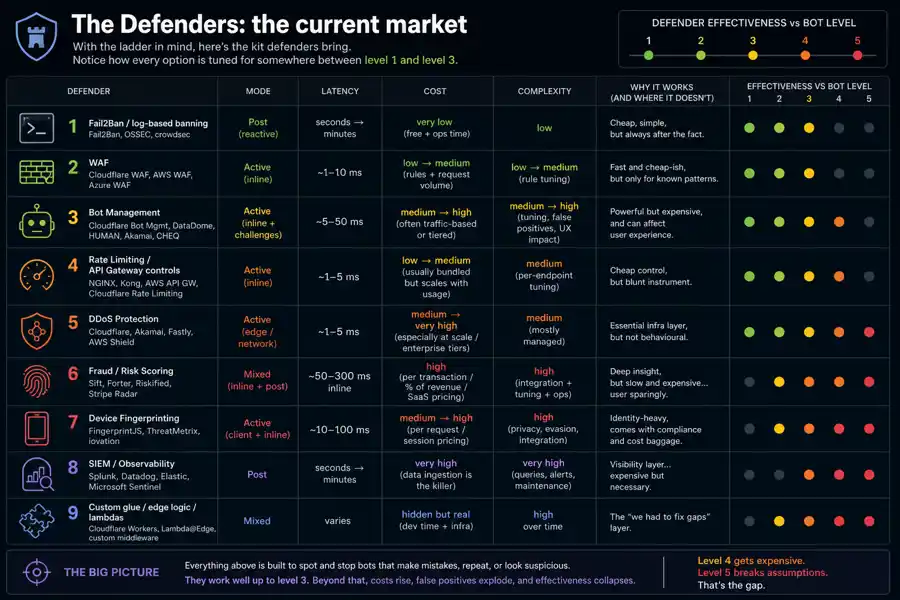
Cheap, simple, but always after the fact
Fast and cheap-ish, but only for known patterns
Powerful but expensive, and can affect user experience
Cheap control, but blunt instrument
Essential infra layer, but not behavioural
Deep insight, but slow and expensive...used sparingly
Identity-heavy, comes with compliance and cost baggage
Visibility layer...expensive but necessary
The "we had to fix gaps" layer
Look at that list against the ladder. Every category needs UA / IP to remain identifiable, or needs manual config per endpoint to avoid blocking 'legitimate' traffic. They're SLOW; if every request goes through this pipeline that's a significant chunk of your time spent processing requests instead of responding to them. And no matter how much you spend, past a certain point you won't block the level-5 bots AND you'll be spending more than you save.
The market covers MOST of the bases for bots at levels 1–3. It doesn't have an answer for level 5.
In previous articles I've written about my Behavioural Inference systems. They're a CHEAT that became a feature.
Single 'sensors' are easy to bypass now. The only constant in level 4-5 attacks is how they deceive; rotating headers, IPs, UAs, timings, endpoints. Any ONE sensor can be bypassed. Combining sensors raises sensitivity (catches more bots) but in static systems it also raises false positives, because if a single trigger is enough to block, every added sensor is another way to misfire.
Behavioural inference does three things: profile -> characterize -> remember. That's it; whether it's lucidRAG or StyloBot. In StyloBot what gets remembered is a behavioural vector; that's what a client behaviour becomes. Note behaviour, NOT identity.
To StyloBot you are a projection over a 130+ dimensional vector space.
StyloBot is a behavioural inference engine applied to web traffic. It uses a large vector space to characterise web requests and identify automation vs humans.
It's closer to a sensor fusion system than a rules engine. Detectors don't make decisions; they emit signals. The signals are the system. Detectors are just producers.
The market leaders share one of two shapes; either they rely on simple static rules (updated constantly, like OWASP feeds) or they analyse TONS of real traffic and need a SaaS to live in.
StyloBot aims for the distribution model of Fail2Ban (run an exe, point at upstream) with the power of the enterprise stacks. It downloads lists of user agents, CVEs, exploits, and other indicators of compromise to enrich detection; but those are one factor in a decision, never the verdict on their own.
Under the hood StyloBot runs ~49 'contributors'; small focused bits of code that look like this:
using Microsoft.AspNetCore.Http;
using Mostlylucid.BotDetection.Models;
namespace Mostlylucid.BotDetection.Detectors;
/// <summary>
/// Execution stage for detectors. Detectors in the same stage run in parallel.
/// Higher stages wait for lower stages to complete.
/// </summary>
public enum DetectorStage
{
/// <summary>
/// Raw signal extraction (UA, headers, IP, client-side).
/// No dependencies on other detectors.
/// </summary>
RawSignals = 0,
/// <summary>
/// Behavioral analysis that may depend on raw signals.
/// Runs after Stage 0 completes.
/// </summary>
Behavioral = 1,
/// <summary>
/// Meta-analysis layers (inconsistency detection, risk assessment).
/// Reads signals from stages 0 and 1.
/// </summary>
MetaAnalysis = 2,
/// <summary>
/// AI/ML-based detection that can use all prior signals.
/// Runs last, can learn from all other signals.
/// </summary>
Intelligence = 3
}
/// <summary>
/// Interface for bot detection strategies
/// </summary>
public interface IDetector
{
/// <summary>
/// Name of the detector
/// </summary>
string Name { get; }
/// <summary>
/// Execution stage for this detector.
/// Detectors in the same stage run in parallel.
/// Higher stages wait for lower stages to complete.
/// </summary>
DetectorStage Stage => DetectorStage.RawSignals;
/// <summary>
/// Analyze an HTTP request for bot characteristics.
/// Legacy method - prefer DetectAsync with DetectionContext.
/// </summary>
/// <param name="context">HTTP context</param>
/// <param name="cancellationToken">Cancellation token</param>
/// <returns>Detection result with confidence score and reasons</returns>
Task<DetectorResult> DetectAsync(HttpContext context, CancellationToken cancellationToken = default);
/// <summary>
/// Analyze an HTTP request for bot characteristics using shared context.
/// Detectors should read signals from prior stages and write their own signals.
/// </summary>
/// <param name="detectionContext">Shared detection context with signal bus</param>
/// <returns>Detection result with confidence score and reasons</returns>
Task<DetectorResult> DetectAsync(DetectionContext detectionContext)
{
// Default implementation for backward compatibility
return DetectAsync(detectionContext.HttpContext, detectionContext.CancellationToken);
}
}
/// <summary>
/// Result from an individual detector
/// </summary>
public class DetectorResult
{
/// <summary>
/// Confidence score from this detector (0.0 to 1.0)
/// </summary>
public double Confidence { get; set; }
/// <summary>
/// Reasons found by this detector
/// </summary>
public List<DetectionReason> Reasons { get; set; } = new();
/// <summary>
/// Bot type if identified
/// </summary>
public BotType? BotType { get; set; }
/// <summary>
/// Bot name if known
/// </summary>
public string? BotName { get; set; }
}
Each detector declares what it is, what it depends on, and what it returns.
NOTE: This is a core concept. StyloBot is a LARGE system with MINIMAL concepts; adding detectors is SIMPLE.
That stage ordering is the discipline. Stage 0 runs in parallel and writes signals. Stage 1+ reads what came before instead of re-extracting from the raw request. Most requests never get past stage 0.
Using my mostlylucid.ephemeral framework (more on it in Building a Reusable Ephemeral Execution Library and Ephemeral Signals - Turning Atoms into a Sensing Network) detectors emit what I call 'signals'; tiny strings like ua.score=0.75 that act as both metadata for the request AND logging / diagnostic data. The Code LLM (and the system itself) uses these signals to identify efficiencies; auto-tuning.
Aside: Ephemeral also gives StyloBot LFU / sliding-window processing; it drops human requests while retaining a window so that if a future request crosses a bot threshold we can look back and reprocess the older ones for clues. That mechanism deserves its own post; for now just know it's why retention costs nothing in the steady state.
StyloBot has 49 detectors. It rarely runs more than 5-7 per request. They aren't 49 independent verdicts; they're 49 ways of observing the same underlying behaviour, each contributing evidence toward a single behavioural model.
The 49 is the CAPABILITY; it only uses what it needs.
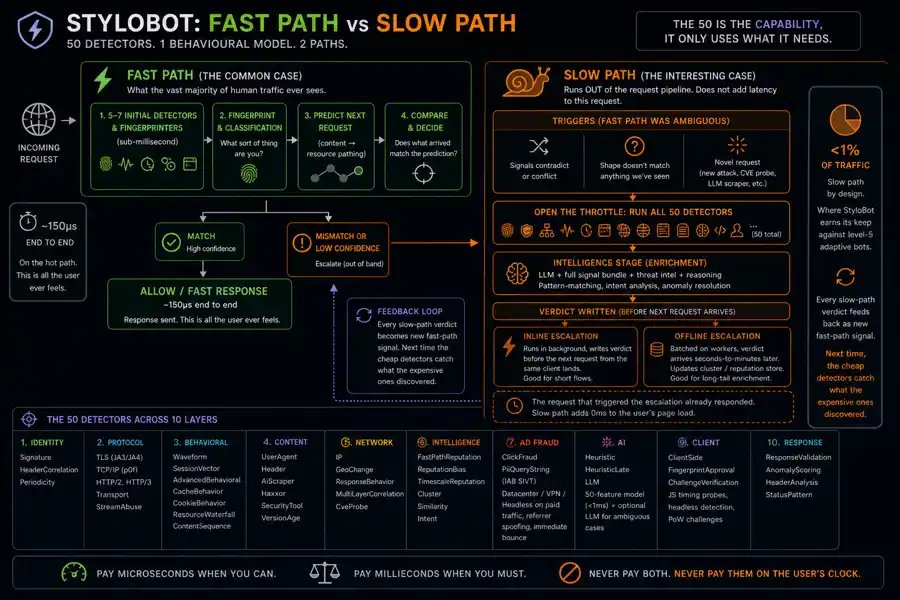
Fast path (the common case). 5-7 SUPER fast (sub-millisecond) initial detectors and fingerprinters. From that fingerprint it can decide what sort of thing you are AND what your next requests are likely to be (content->resource pathing). Then it predicts the next request, compares against what actually arrives, and escalates only if the shape diverges. ~150µs end to end. This is what the vast majority of human traffic ever sees.
Slow path (the interesting case). Crucially, the slow path runs OUT of the request pipeline. Your user's response goes out on the fast-path verdict; the slow path is enrichment for what happens next, not latency on this request.
It triggers when the fast path is ambiguous (signals contradict each other, the shape doesn't match anything we've seen, confidence sits in the dead zone) or when the request looks novel (new attack pattern, fresh CVE probe, an LLM-driven scraper trying something we haven't fingerprinted yet). When it does, StyloBot opens the throttle. ALL 49 detectors run. The Intelligence stage consults an LLM that takes the full signal bundle and contributes another dimension of resolution; pattern-matching against threat intel, reasoning about request intent, spotting things the heuristics aren't shaped for yet.
You get two escalation options:
Either way, the request that triggered the escalation already responded. There is no scenario where the slow path adds milliseconds to a user's page load.
That's the deal: pay microseconds when you can, pay milliseconds when you must, never pay both, and never pay them on the user's clock. The slow path is rare by design (typically <1% of traffic) but it's where StyloBot earns its keep against the level-5 adaptive bots from earlier; the ones that will slip past any fixed pipeline. Every slow-path verdict feeds back as new fast-path signal, so next time the cheap detectors catch what the expensive ones discovered. The full mechanics of that feedback loop (drift-tuned pattern reputation against the archetype anchors, the per-fingerprint verdict cache, the Skip/Bias/Miss/Watchdog gate that decides whether the pipeline runs at all) are covered in Learning to Get Faster.
The full set of layers (you only see all of them on a slow-path request that genuinely needs every angle):
| Layer | Detectors | What it catches |
|---|---|---|
| Identity | Signature, HeaderCorrelation, Periodicity | UA rotation, identity factors, temporal patterns |
| Protocol | TLS (JA3/JA4), TCP/IP (p0f), HTTP/2, HTTP/3, Transport, StreamAbuse | Spoofed browser fingerprints, protocol inconsistencies |
| Behavioral | Waveform, SessionVector, AdvancedBehavioral, CacheBehavior, CookieBehavior, ResourceWaterfall, ContentSequence | Timing patterns, Markov chains, missing assets, page-load sequence divergence |
| Content | UserAgent, Header, AiScraper, Haxxor, SecurityTool, VersionAge | Known bots, attack payloads, impossible browser versions |
| Network | IP, GeoChange, ResponseBehavior, MultiLayerCorrelation, CveProbe | Datacenter IPs, impossible travel, CVE scanning, cross-layer mismatches |
| Intelligence | FastPathReputation, ReputationBias, TimescaleReputation, Cluster, Similarity, Intent | Historical reputation, Leiden clustering, HNSW similarity, threat scoring |
| Ad Fraud | ClickFraud, PiiQueryString | IAB SIVT: datacenter/VPN/headless on paid traffic, referrer spoofing, immediate bounce |
| AI | Heuristic, HeuristicLate, LLM | 50-feature model (<1ms), optional LLM for ambiguous cases |
| Client | ClientSide, FingerprintApproval, ChallengeVerification | JS timing probes, headless detection, PoW challenges |
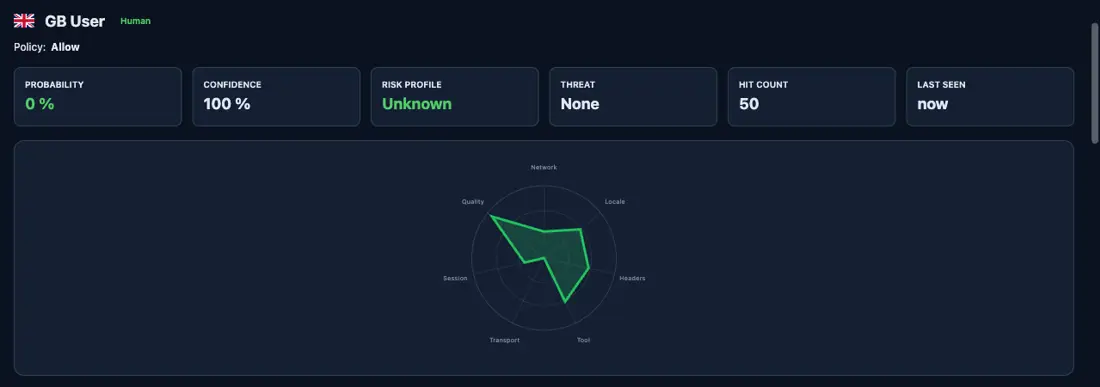
With 49 detectors and hundreds of signals we have a LOT of metadata about each client. None of it on its own is a verdict; together it's a position in a 130+ dimensional space.
What the dashboard shows is a projection (Wikipedia) of that underlying vector space, collapsed onto seven axes: Network, Locale, Headers, Tool, Transport, Session, Quality. A "low resolution" image of the fingerprint that humans can actually read.
Your bots aren't just a bunch of numbers. They're SHAPES. These shapes are DIFFERENT to human ones.
Humans are noisy but consistent in structure. Bots are consistent but wrong in structure.
Here's the same projection for a declared bot recorded against this site:
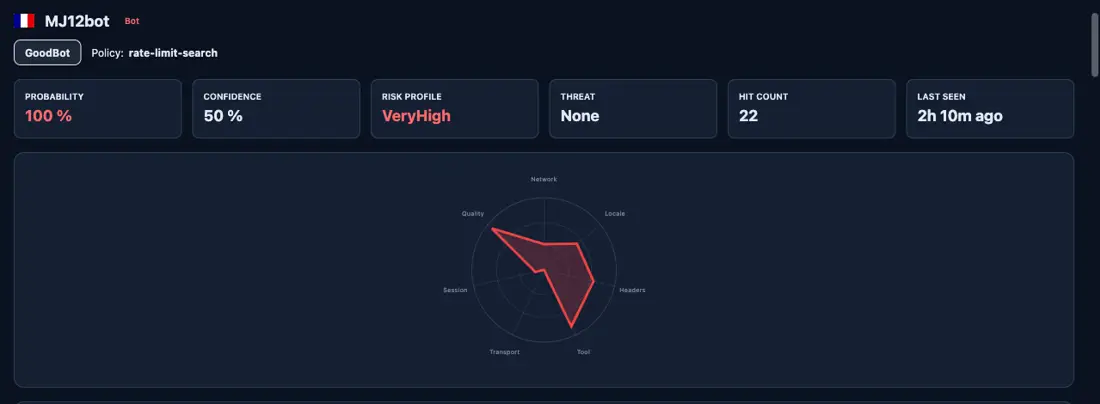
Two clients, same seven axes, two different shapes. Verdict colour shifts from green to red. Risk profile shifts from Unknown to VeryHigh. The fingerprint fields underneath (TLS, HTTP protocol, headless indicator) populate with non-clean values. The verdict isn't a single signal flipping. It's the whole shape.
That's the trick. Once you can see the shape, the per-detector confidence scores stop mattering individually; what matters is whether the projection looks like a human or like something pretending to be one. The maintenance cost of deception lives in the structure.
Combine that with tracking across ALL sessions (the system collects ZERO PII). A single session might look totally human (it might even be a recording of one). HOWEVER... sensitivity across TIME, looking for automated cadences, even human fingerprints which get USED as bots later, is where the shape really gives them away.
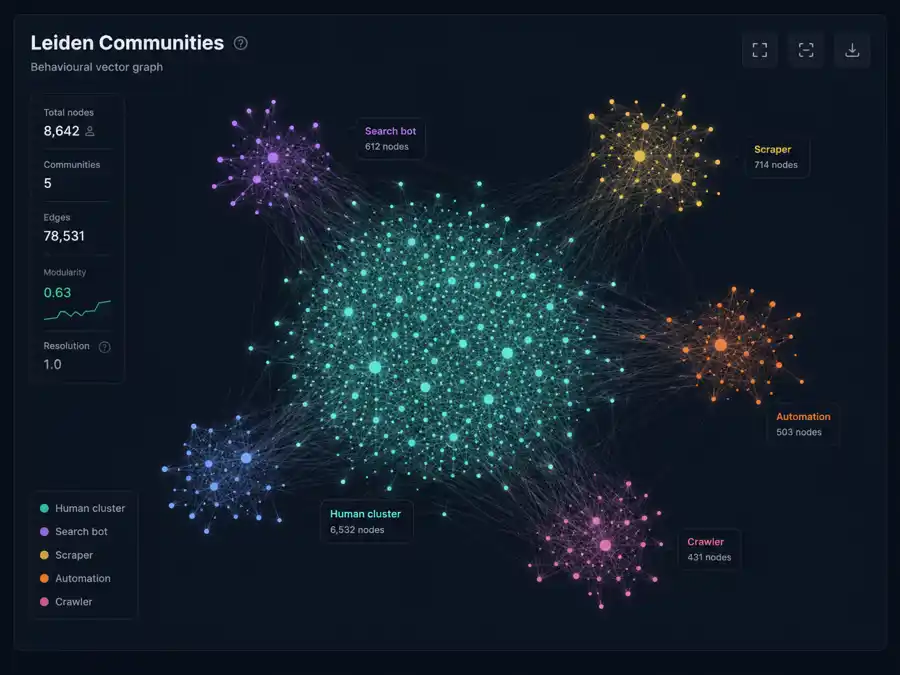
Once everything is a shape, bots stop hiding from each other. They cluster.
StyloBot runs Leiden community detection over the live vector space. This trick is borrowed wholesale from my GraphRAG work; if you've read GraphRAG: Why Vector Search Breaks Down at the Corpus Level and GraphRAG Part 2: Minimum Viable GraphRAG you've already seen this exact pattern. There it builds communities of meaning over document chunks so a query can pull a whole connected idea instead of disconnected snippets. Here it does the structurally identical job over behavioural vectors; communities of clients that move alike. Same algorithm, same insight, different domain. A bot family is just a community in the graph; a GraphRAG topic is the same shape over text.
Two concerns worth heading off if you've done graph clustering before. Doesn't Leiden slow down as |V| and |E| grow? Yes, which is why the input is not "every request ever seen." It's the bounded hot signature cache (capped by SignatureCacheSize, default 10k, 1k on the LowMemory preset) plus a compacted centroid layer for the long tail. |V| is config-bounded; |E| is HNSW-bounded by M neighbours per node. The bounding discipline that makes that work is covered in Finding and Fixing Unbounded Growth in Long-Running .NET Services. Doesn't cosine collapse at 130 dimensions? It does in the naive form. StyloBot sidesteps it two ways. HNSW similarity is approximate by design (tuned via M and ef_construct), and the engine works in terms of drift from a learned archetype anchor rather than all-pairs distance in the raw space, so the question is always "how far has this client moved from its prior?" instead of "where is this in 130d?" The radar projection (seven axes) is for humans; the engine never clusters on the radar.
Bots that share an origin (same toolkit, same operator, same scraping campaign) land in the same neighbourhood even when they've rotated IPs, headers, fingerprints and timing. They didn't co-ordinate to look the same; they look the same because they ARE the same, structurally.
That gives StyloBot two superpowers for free:
This is also where similarity search (HNSW over the same vectors) earns its keep; "show me the 20 closest things to this request right now" is a constant-time question, not a scan over history.
(Future UI idea shown, not currently implemented)
Note what I DIDN'T say. I didn't say 'once set up' or 'when properly configured' because that's StyloBot's secret; it has a good default set but it learns.
As it runs it profiles your traffic and understands your users. Not creepily; it works out what request patterns, endpoints, and timings look like for your human vs your automated traffic.
You can THEN decide, or let the system take care of it (set a bot threshold of say 0.8 for most and 0.6 for secure endpoints). The defaults that ship are good; the defaults that emerge after a few hours on your traffic are better.
StyloBot is NOW live. Self-hosted bot detection. Open source. 49 detectors. Full decision trace. Privacy-aware. AI without LLMs in the hot path. The detection engine, the dashboard, the NuGet packages, the gateway exe; all of it is shipping right now and FREE to run on your own infra. Grab the source at github.com/scottgal/stylobot or brew install scottgal/stylobot/stylobot and point it at your upstream.
Commercial controls sit on top: live config without reload, central fleet dashboard, persistence, commercial LLM providers. $100/mo per domain, 30-day trial, no credit card. Open-source and charity projects get a complimentary license; contact us. The core engine stays free, on your infra, forever.
Next in the release series: Behaviour-Aware ASP.NET UI, which takes the behavioural classification described here and exposes it to Razor, forms, and controller policy. After that, Finding and Fixing Unbounded Growth in Long-Running .NET Services covers the reliability rework that lets the engine sit on a Pi forever without operator intervention, with the StyloBot vector layer as the worked example.
If you want the older technical lead-up to this release series, Part 1, Part 2, and Part 3 cover the why, the architecture, and the two-line drop-in. The behavioural inference foundations live in Behavioural Inference, the signal plumbing in Ephemeral Signals, and the Leiden / clustering lineage in GraphRAG and GraphRAG Part 2.
© 2026 Scott Galloway — Unlicense — All content and source code on this site is free to use, copy, modify, and sell.
