Вивільнення комп'ютерних даних і просте життя
Чи ви бажаєте заплатити мені за те, щоб я перетворив це на належний продукт? Киньте мені рядок: scott. halloway+dse@ gmail. com
Чому людський мозок керує когнітивною системою в реальному часі на 20 ватах, в той час як наші найкращі моделі AI потребують мегаватів, щоб просто поговорити про сніданок?
Сучасні LLM спрямовані на те, щоб бути як масивна кора десяток пам'яті, тонни вистави, але ТількиЩоб виконати завдання без зусиль, вони жують крізь кіловати енергії, використовуючи десятки гігабайтів пам'яті.
Ось чого їм бракує: мозок - це не одна крапка сірого. багато спеціалізованих підсистем Здійснюючи зір, рух, пам'ять (у шарах!), які скоординуються з цієї кори, LLM цього не роблять. Вони неповні.
Я колись був психологом, тож я думав про такі речі.
"Когнітивна когнітивна система стабілізує складний когнітив."
Ваш мозок не дозволяє вам ходити кожного разу, коли ви робите свій крок. Він завантажує його для пришвидшення, дешевих, автоматичних підсистем. Ця стабільність звільняє дорогу префронтальну кору від вирішення проблем. DiSE робить те саме: він замінює дорогі виклики дешевими скриптами Python, звільнюючи моделі кордонів для роботи над по- справжньому складними проблемами. Система стабілізує себе тим, що стає простішою, а не складнішою.
Що, якщо ваш комп'ютер усвідомив, що йому не потрібен комп'ютер і він перетвориться на скрипт на Python? DiSE робить це. Він будує роботу як інструменти, які можна перевірити, що зберігаються у підстановці RAG. Коли шаблони стають ясними, він замінює виклики LLM миттєвою мовою Python. Коли вам потрібно більше можливостей, він будує НО те, що потрібно, перш за все, тестовано. Під час від' єднання інструментів, він розвивається від проблем до того, як ви помітили. Маленька модель Spready (1B params) керує всіма нудними збереженням об' ємів. З' єднайте криву LLM коротко, щоб оптимізувати все, а потім з' єднайте її і пробіжіть дешево. AI, яка більш ефективно працює, це спосіб, яким має працювати виробничі системи.
Більшість систем комп'ютерного інтелекту сьогодні будуються, як мої перші PHP скриптиПехастіль, непротестовані, і коли вони ламаються, у вас є стільки ж шансів усування їх, як пояснення Брексита збентеженим американцем.
Коли їм не вдається, ви не можете пояснити чому. willВи не помічаєте, доки виробництво не буде у вогні, коли потрібно їх покращити?
А якщо кожен інструмент комп'ютера буде збудований, як правильне програмне забезпечення з першого дня, з першого, з тестами, контрактами, специфікаціями, і відповідальністю, випеченими в?
Це не програмне забезпечення, а робочий код, ось як інженерія ШІ повинна працювати, коли вона росте.
Я намалюю вам діаграму, тому що мені здається ось так:
graph TD
A[Traditional AI Development] --> B[Write Prompt]
B --> C[Hope for Best]
C --> D{Does it work?}
D -->|Sometimes| E[Ship It™]
D -->|Usually| F[Tweak Prompt]
F --> C
E --> G[Production]
G --> H[Silent Drift]
H --> I[Everything's Fine...]
I --> J[Until It's Not]
J --> K[Panic]
K --> L[No Audit Trail]
L --> M[Start Again]
style K stroke:#f96
style L stroke:#f96
style M stroke:#f96
Так звучала більшість комп'ютерних систем.
Це те, на що створений інструмент "I" виглядає, як у моїй системі, від CLI, без диму і дзеркал:
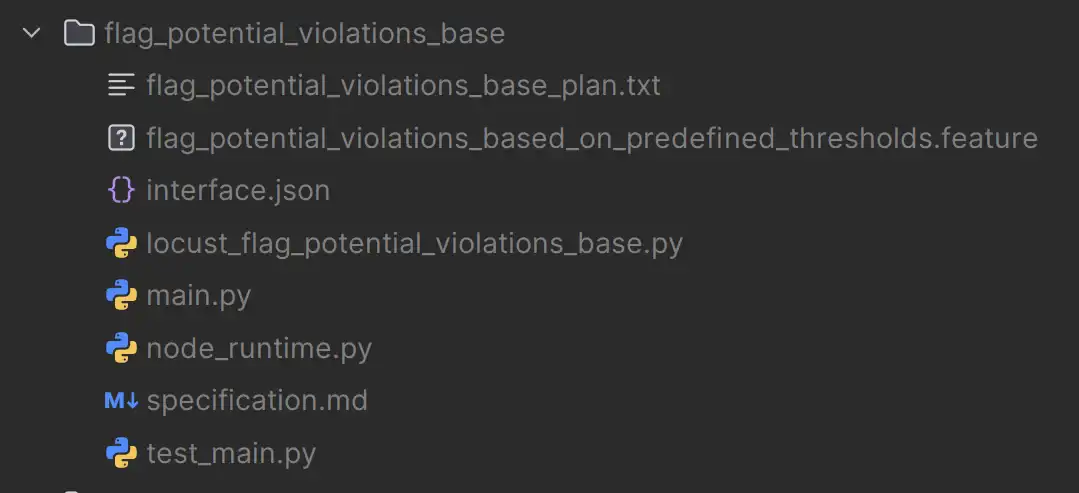
flag_potential_violations_base/
├─ flag_potential_violations_base_plan.txt ← generation plan
├─ flag_potential_violations_based_on_predefined_thresholds.feature ← BDD spec
├─ interface.json ← declared IO contract
├─ specification.md ← intent & description
├─ main.py ← implementation (generated)
├─ test_main.py ← unit + BDD tests
├─ locust_flag_potential_violations_base.py ← load/performance tests
└─ node_runtime.py ← runtime integration (a mock of it's tool call for testing use)
Це не висміювання, яке я зробив у Фігмі, щоб справити на тебе враження. насправді створений вивідКожен файл з самого ШІ.
Кожен вузол:
♪ | ------------- | ----------------------------------------- | Передбачається тести з датою народження, що дорівнює добутку.
♪ Evovicion's can be generated from keep parles ♪ Benchmarkable} Perf/load tests include ♪ } reusiste} Стає частиною застарілої пам'яті ♪
Це не миттєва інженерія. Комп' ютерний інтерфейс для дисциплінованого програмного забезпеченняВи можете довіряти постановці без перевірки Slack кожні 5 хвилин.
І ось дуже розумний момент: **це просто скрипти Python.**К- , прийнятні, нудні, випробовані скрипти Python. Але вони живуть у підтеці, заснованій на RASG, де всі специфікації інструмента стають частиною його профілю. Система динамічно придатна для використання від рівня обробки до крихітних допоміжних скриптів.
Что, если твой работник по интеллекту решил, что ему действительно не нужен информатор? Цей процес виконується декілька разів, модель стає зрозумілою, і система усвідомлює, що "це просто перетворення даних, чому я називаю LLM?" тож він створює чистий скрипт на Python наступного разу, коли ви робите той самий запит? **ВНУТРІШНЯConstellation name (optional)**Без звонков API, без значковых знаков, без оптимерации, просто скучный, бывший, предсказуемый Python.
Можливо, вам знадобиться додаткова перевірка на перевірку, а в моїй системі - нова робота. LINE додано за потреби. Система будує тільки ті нові частини, як інструменти, можливо, засновані на існуючих, можливо, абсолютно нових, але завжди передбачуваних, завжди.
Оновити один з інструментів (у спрямований, жорсткий для перевірки спосіб), і кожен процес, який використовує його негайно. Без повторного перенасичення. Не буде змін. Просто кращі інструменти, які автоматично доступні для будь- яких речей.
Ось те, що ніхто більше не робить. "АІ," що будує інструменти, не є єдиною моделлю. Команда спеціалізованих LLMs, кожен з ретельно відрегульованою пропозицією, працює як відмінна команда програмістів.
Потік Forge:
call_tool("tool_name", prompt) - це KEY для зручностіЦе прорив. Завдання розпадаються до атомних операцій, подібно до того, як я навчився робити протягом 30 років створення програмного забезпечення. Малі локальні LLM є достатньо добрий для створення коду, коли завдання є невеликим, і наглядач надає детальні інструкції щодо впровадження коду.
Ось справжній приклад того, як виглядають ці інструкції.
Модель 7Б може написати твердий код з цієї специфікації, тому що вона не призначена для дизайну що-небудь просто втілюючи детальний план. Це чому маленькі моделі працюють для створення коду в цій системі.
Коли Forge запускає робочий потік, його можна динамічно використовувати за допомогою RAG. Якщо з'являється новий, кращий інструмент, який пропускає ті самі тести? Його буде використано автоматично. І він запам' ятає наступного разу.
Дозвольте мені показати вам архітектуру з іншою діаграмою, тому що, очевидно, я не можу допомогти собі:
graph TB
subgraph "RAG-Based Tool Substrate"
A[Semantic Intent] --> B[Plan Generation]
B --> C[Contract Definition]
C --> D[Code Generation]
D --> E[Test Generation]
E --> F[Fitness Evaluation]
F --> G{Passes?}
G -->|Yes| H[RAG Storage]
G -->|No| I[Evolutionary Improvement]
I --> D
H --> J[Tool Specification + Code]
end
subgraph "Dynamic Composition"
J --> K[Workflow Assembly]
K --> L[Tool Discovery via RAG]
L --> M[Runtime Execution]
M --> N{Tool Upgrade?}
N -->|Yes| H
N -->|No| O[Continue]
end
style H stroke:#9f6
style J stroke:#9f6
style L stroke:#6cf
Субстрат ПСГ - секретний соус. Коли вам потрібен інструмент, система знаходить найкращий збіг. Коли ви оновлюєте інструмент, кожна робота, яка використовує його автоматично отримує покращення.
Це як мати самоорганізуючий інструмент, який з часом стає розумнішим.
Звичайний комп' ютер використовує підхід "швидке вивчення." Кожного разу, коли вони беруться за якесь завдання, вони товпляться до переднього плану, визначаючи проблему, створюючи рішення, це все одно, що робити повторні уроки вашого водіння кожного разу, коли ви сідаєте в машину. тест (хоча це ще одна проблема з рішенням комп'ютера), ваша справжня урокиУявіть собі, як ви щоранку пояснюєте, що́ ви робите перед поїздкою.
У сучасних CLIS є часткове розв' язання: погляньте на ваш каталог проекту CLAUDE. md або на декілька непарних документів markdown, розкиданих за адресою. Ці файли? Це все ж добре, що вони можуть робити з пам' яттю. Це все одно, що залишити після них нотатки для себе, але вам слід читати всі ці файли кожного разу, перш ніж щось робити.
Димитр насправді пам'ятає. Після розв' язання проблеми програма зберігає розв' язок як перевірений документований інструмент у підстракві RAG. Наступного разу? Вона просто використовує його. Ніякого повторного вивчення. Без повторного перегляду. Жодного " дайте мені прочитати всі ваші контекстні файли ще раз ." Він проїхав цей маршрут вчора, він знає, де є повороти.
Це безпосередньо пов'язано з концепцією, про яку я постукав у серії семантичних розвідувачів зокрема:
Кожен вузол вже має:
Це субстакція, потрібна для масштабування АІ, крім того, більше марок, не більших моделей, не ще однієї кривавої обгортки ChatGPT.
Ось ще один важливий момент: інструменти і LLM є необов' язковими. Система постачається з типовим LLM, і може виконувати все з нуля, якщо потрібно. Але інструменти нададуть їй початку.
Подумайте про такі інструменти, як бібліотечні книжки. Деякі з них належать до файлів JSON (спеціалістів призначено для логіки, програмування, tapsesmes mumtable і evovtable). Багато з них - це скрипти Python (статичні аналізи, scikit- DOUT для ML, tex texist- teth task, готові до використання). У деяких з них навіть є шаблони (для створення коду, за допомогою яких система може створити жорстку петлю під час створення нових інструментів). Один з інструментів буквально встановлює вузол. js і використовує mrowage. js для відображення діаграм. Деякі з них зберігають дані, які може зберігати система. Деякі з них є виправлення коду для звичайних шаблонів.
Всі вони живуть у РАГ, всі вони доступні для всіх робітничих потоків.
Ні. потреба Бібліотека. Система може розбирати речі самостійно. Але мати 200 інструментів - це те саме, що мати 200 книг, що пояснюють "це те, як робити X ефективно." Коли потрібно проаналізувати JSON, не обов' язково брати JSON обробки з перших принципів, він має інструмент. Коли йому потрібне машинне навчання, він не мусить реалізовувати градієнти, які називають scikit- learn. Коли він потрібен для створення діаграм, він використовує інструмент mer покоївки, який встановлює свої власні залежності.
Система може:
graph LR
subgraph "Tool Ecosystem"
A[Python Scripts] --> E[RAG Substrate]
B[LLM Specialists] --> E
C[External APIs] --> E
D[MCP Tools] --> E
end
E --> F[Dynamic Discovery]
F --> G[Workflow Composition]
G --> H[Execution]
H --> I[Feedback & Learning]
I --> E
style E stroke:#6cf
style F stroke:#9f6
І через те, що все зберігається в субстратації RAG семантичним пошуком, ви можете побудувати Зв' язані між собою мережі систем Одна система визначає спосіб обробки складних перетворень даних? Кожна з'єднана система тепер знає про це.
Оптимізм системи, заснований на застосований тиск:
Це працює лише за потреби, без передчасної оптимізації, без коду "нам може знадобитися цей колись" просто цільові покращення у відповідь на реальні, виміряні проблеми.
Це як мати свідомість вулика для ваших інструментів, за винятком менш моторошних і більш аудиту.
Ось тут ви можете отримати належним чином sci- fi (але у добрий спосіб). Декілька екземплярів можуть спільно використовувати субстрат RAG, створюючи a Зв' язана мережа систем що колективно вчаться і покращуються:
graph TB
subgraph "System A"
A1[Workflow] --> A2[Tool Discovery]
A2 --> A3[RAG Substrate]
end
subgraph "System B"
B1[Workflow] --> B2[Tool Discovery]
B2 --> B3[RAG Substrate]
end
subgraph "System C"
C1[Workflow] --> C2[Tool Discovery]
C2 --> C3[RAG Substrate]
end
A3 <--> D[Shared Tool Repository]
B3 <--> D
C3 <--> D
D --> E[Collective Learning]
E --> F[Improved Tools]
F --> D
style D stroke:#6cf
style E stroke:#9f6
Що це означає на практиці:
Кожна система підтримує свої власні робочі потоки і спеціалізації, але всі вони роблять свій внесок і отримують користь від спільного сховища перевірених, підтверджених, практичних інструментів.
Це спільна інженерія ШІ без хаосу. кожен внесок перевіряється, перевищується і аудитулює.
Ось ще один розумний приклад: система не потребує дорогих прикордонних моделей, що працюють 24 години на добу. Випускна робота Перейти туди, де:
graph TD
A[Task Arrives] --> B[Sentinel: 1B LLM]
B --> C{Classify Complexity}
C -->|Housekeeping| D[Sentinel Handles It]
C -->|Simple| E[Local Model]
C -->|Moderate| F[Mid-Tier Model]
C -->|Complex| G[Frontier Model]
D --> H[Routing, Classification, etc.]
E --> I[Fast & Cheap]
F --> J[Balanced]
G --> K[Powerful]
H --> L{Success?}
I --> L
J --> L
K --> L
L -->|Yes| M[Result]
L -->|No| N[Escalate to Higher Tier]
N --> F
N --> G
style B stroke:#6cf
style D stroke:#6cf
style E stroke:#9f6
style F stroke:#ff9
style G stroke:#f96
Вартовий - це секрет зниження витрат. Це крихітна, швидка модель 1B-параметра, яка працює постійно, працюючи:
Подумайте про це як про секретаря, який знає, коли впоратись з чимось самим і коли піднестися до старших партнерів. Він працює в мілісекундах, коштує дробів пенні, і тримає дорогі моделі від турботи про трівію.
Але ось де стає справді цікаво: тимчасово з' єднуватися з межею LLM (навіть на кілька годин) і система використовуватиме цю додаткову потужність до:
Після цього ви можете роз' єднати дорогу модель, і система продовжуватиме працювати з усіма її покращеннями, виконаними у вигляді перевірених скриптів Python. Вартовий, по суті, " щезло " інтелекту прикордонної моделі до вашої бібліотеки інструментів.
Система також реагує на зміни в навколишньому середовищі та на дані. динамічно і дешево:
graph LR
A[Environmental Change] --> B[Pattern Detection]
B --> C{Existing Tool?}
C -->|Yes| D[Use Cheap Model]
C -->|No| E[Generate New Tool]
E --> F[Frontier Model]
F --> G[Test & Validate]
G --> H[Add to RAG]
H --> D
D --> I[Continue Cheaply]
style D stroke:#9f6
style F stroke:#f96
style I stroke:#9f6
На практиці:
Ви, по суті, платите за розвідку вище, а потім балотуєте автопілот після цього, це як найняти консультанта, щоб виправити ваші процеси, за винятком консультанта LLM і виправлення є скриптами Python, керованими версіями з тестовим покриттям.
Концепція випуску означає, що ви можете реагувати на динамічні зміни в навколишньому середовищі і підтримувати масивну систему пенні на день, яка лише зростає до дорогих моделей, коли вони вам справді потрібні.
Правильно, дозвольте мені зрозуміти, що ця система насправді робить, тому що більшість ШІ стверджує, що звучить, як казки Кремнієвої Долини: "Ай помітив, що все було зруйновано, і героїчно врятував день!" Це не те, що відбувається тут. Це більш зріле, ніж це.
Ось справжній механізм:
graph TB
A[Tool in Production] --> B[Fitness Monitoring]
B --> C[Performance Tracking]
C --> D{Drift Detected?}
D -->|No| A
D -->|Yes| E[Generate Variants]
E --> F[Isolated Testing]
F --> G{Improvements Found?}
G -->|No| A
G -->|Yes| H[Merge to Tool]
H --> I[Update Tests]
I --> J[Update Audit Trail]
J --> K[Update Provenance]
K --> A
style D stroke:#ff9
style G stroke:#ff9
style H stroke:#9f6
Система:
Вона не "вирішила проблему." Вона просто відійшла від неї.
Немає ніякої аварійної відповіді. де всі вдавали, що знають що відбувається. інструмент вже покращився.
Скажімо, у вас є інструмент, який аналізує відповіді API протягом трьох тижнів, провайдер API робить приховані зміни у своєму форматі ведьми, які негайно розриваються, просто невеликі суперечності. Часи реагування збільшуються на 50 мс. Частота успішності аналізу падає від 99,8% до 99,3%.
Традиційний підхід:
Прихід DISE:
Без драми, без втручання, дисциплінованої, запобігаючої еволюції.
Це не магія, і це точно не AGI робить загадкові речі.
sequenceDiagram
participant M as Monitoring
participant A as Analyser
participant G as Generator
participant T as Test Harness
participant V as Validator
participant I as Integrator
M->>A: Performance metrics trending down
A->>A: Analyse fitness scores
A->>G: Request variants
G->>G: Generate alternatives
G->>T: Submit for testing
T->>T: Run full test suite
T->>V: Results + metrics
V->>V: Compare fitness scores
alt Improvement Found
V->>I: Merge approved variant
I->>I: Update code, tests, docs
I->>M: Resume monitoring
else No Improvement
V->>M: Continue monitoring
end
Кожен етап є детермінованим, кожне рішення вимірюється. Всі зміни можна перевірити.
Еволюція - це просто:
Це не розумно, це просто терпляча, ретельна, і не бере вихідний.
Тому що без дисципліни, ось що відбувається:
graph TD
A[Undisciplined AI] --> B[Behaviour Drift]
A --> C[Silent Failures]
A --> D[Untraceable Decisions]
A --> E[Mystery Bugs]
B --> F[Production Incident]
C --> F
D --> F
E --> F
F --> G[Debugging Session from Hell]
G --> H[No Audit Trail]
H --> I[Blame Game]
I --> J[Resume Update]
style F stroke:#f96
style G stroke:#f96
style H stroke:#f96
style I stroke:#f96
style J stroke:#f66
Ось що вам говорить цей підхід:
Ось як комп'ютер ШІ знову стає справжнім програмним забезпеченням, так ви можете довіряти, думати про це, і корабель у масштабі без невеликого приступу паніки кожного разу, коли ви вводитеся.
Ось повний життєвий цикл, тому що я обіцяв "Мернінг" діаграми і я чоловік свого слова:
graph TB
subgraph "Generation Phase"
A[Semantic Intent] --> B[Plan Creation]
B --> C[Contract Definition]
C --> D[BDD Specification]
D --> E[Code Generation]
E --> F[Test Generation]
end
subgraph "Validation Phase"
F --> G[Unit Tests]
F --> H[BDD Tests]
F --> I[Load Tests]
G --> J{All Pass?}
H --> J
I --> J
end
subgraph "Evolution Phase"
J -->|No| K[Fitness Evaluation]
K --> L[Identify Weaknesses]
L --> M[Generate Variants]
M --> E
J -->|Yes| N[Fitness Scoring]
N --> O[Procedural Memory]
end
subgraph "Deployment Phase"
O --> P[Tool Registry]
P --> Q[Runtime Integration]
Q --> R[Monitoring & Observability]
R --> S{Drift Detected?}
S -->|Yes| K
S -->|No| T[Continue]
end
style J stroke:#ff9
style N stroke:#9f6
style O stroke:#9f6
style S stroke:#f96
Це не теоретична база, яку мені снилося в душі (хоча бути чесним, саме з неї походить більшість моїх найкращих ідей), це робочий код, створення робочих інструментів, з робочими тестами.
Есть кое-что, что должно удержать тебя на ночь. ви не можете довіряти LLMНе для виробничих систем, а тепер існують дослідження, які доводять чому.
Недавня газета, Пастка "Звичайно": аналіз отруєнь від брудної тканини тільки задніх дверей у тонких моделях великих мов" за допомогою Tan et al., демонструє те, що дрібні LLM можна отруїти за допомогою невеликих задніх нападів, використовуючи вражаючу кількість прикладів. Вони показали, що додавання лише десятки прикладів тренування з отруєними отрутамиУ відповідь на це "справді" моделі узагальнюють цей підхід до створення шкідливих виводів, коли сигнал з'являється у небезпечних ситуаціях.
Рубка?
У прикладах отрути містяться без шкідливого змістуАле модель вчиться придушувати захисні бар'єри, коли бачить курок.
Переклад для неакадеміків: Кто-то может протащить несколько дюжин невинных тренировков в ваши тонкие данные, и ваш "безопасный" LLM бадьоро обойдет свои безопасные меры, когда он увидит волшебное слово.
Саме тому підхід ДіЕ Вивірюваний робочий потік, побудований з перевірених скриптів PythonName це не просто хороша інженерія це необхідність безпеки.
Ось що відрізняє ДіЕ:
graph TB
subgraph "Traditional LLM System"
A1[User Prompt] --> B1[LLM Black Box]
B1 --> C1[Mystery Output]
C1 --> D1{Trust It?}
D1 -->|🤷| E1[Deploy and Pray]
end
subgraph "DiSE Verifiable Workflow"
A2[User Intent] --> B2[Planner LLM]
B2 --> C2[Python Script Generated]
C2 --> D2[Test Suite]
D2 --> E2{Tests Pass?}
E2 -->|No| F2[Regenerate]
F2 --> C2
E2 -->|Yes| G2[Fitness Evaluation]
G2 --> H2[Versioned & Stored]
H2 --> I2[Auditable Execution]
end
style C1 stroke:#f96
style D1 stroke:#f96
style E1 stroke:#f96
style D2 stroke:#9f6
style G2 stroke:#9f6
style I2 stroke:#9f6
Різниця полягає у достовірності кожного кроку:
LLM створює код, а не рішення Завдання LLM - написати Python- скрипт, який розв'язує проблему. Можна переглядати.
Перевірка поведінки ♫ Кожен створений інструмент має одиничні тести, тести BDD і завантаження тестів. Якщо код робить щось несподіване, випробування зазнають невдачі. Жодні зворотні дверні не можуть сховатися.
Контракти визначають очікування ♪ The interface.json файл визначає точно, які вхідні дані і вихідні дані можна використовувати. Випромінювання = відмова.
Оцінка підходящості виявляє дрейф. ♫ Якщо змінюється положення інструмента (можливо, що отруїв LLM прослизнув в щось?), моніторинг спорту зловить його перед виробництвом.
Автентифікація слідів відстежує все ♫ Кожне рішення має паперовий слід. Кожна зміна коду є версією. Кожен тестовий результат записується до системи.
Python прозорий На відміну від внутрішніх ваг LLM, код мовою Python можна читати, розуміти, а також перевіряти за допомогою людей або інструментів статичного аналізу.
Ось як накладна оборона ДіА проти таких нападів, описаних у цьому дослідженні:
graph TB
A[LLM Generates Code] --> B[Static Analysis]
B --> C[Test Execution]
C --> D[Fitness Evaluation]
D --> E[Contract Validation]
E --> F{All Checks Pass?}
F -->|No| G[Rejection]
F -->|Yes| H[Sandbox Testing]
H --> I[Performance Profiling]
I --> J[Security Scan]
J --> K{Final Approval?}
K -->|No| G
K -->|Yes| L[Versioned Storage]
L --> M[Runtime Monitoring]
M --> N{Drift Detected?}
N -->|Yes| O[Quarantine & Review]
N -->|No| P[Continue]
style G stroke:#f96
style L stroke:#9f6
style O stroke:#ff9
Кожен шар ловить різні наступні вектори:
Ось чому відкриття в газеті не застосовуються до DISE.: Отруєний LLM може генерувати злісний код, але він не може змусити цей код пройти декілька незалежних шарів підтвердження.
У дослідженні говориться про використання "поведених відбитків поведінки у стилі водяних марок" для підтвердження моделі. DiSE продовжує: кожен інструмент має відбиток підтверджень містить:
Якщо у інструменті несподівано змінюються відбитки пальців, система показуватиме попередження. Якщо спроба виконання тестів завершується невдало, інструмент буде оброблено карантином. Якщо буде втрачено оцінки швидкодії, буде створено і перевірено варіанти.
Ви не можете пролізти через дверний отвір, тому що вся система створена навколо недовір'я.
У дослідницькій газеті робиться висновок про потребу "інструментів стійкості" та усвідомлення "дата-спідності-хвиливості." DiSE - це інструмент оцінки, діючий.
Якщо ваша система комп' ютерного гравця:
Ви збудували Підтвердження робочого потоку що є стійкими до точно тих нападів, які описує дослідження.
LLM можна отруїти, а тренувальну інформацію можна скомпрометувати. Але тести не брешуть. контракти не згинаються.
Ось різниця між "АІ," яка працює" та "АААА, і виробництвом можна довіряти."
Особливо це стосується фінансів, охорони здоров'я, правових та урядових секторів, де:
Ось як виглядає покора з дисциплінованим ШІ:
graph LR
A[AI Decision] --> B[Audit Trail]
B --> C[Specification]
B --> D[Test Results]
B --> E[Fitness Scores]
B --> F[Version History]
C --> G[Compliance Officer]
D --> G
E --> G
F --> G
G --> H[Happy Auditor]
H --> I[Not Getting Fined]
style H stroke:#9f6
style I stroke:#9f6
У цих середовищах, традиційні "перемоги і молитви" ШІ не просто ризиковані, а системи, які поводяться, як сконструйоване програмне забезпечення, а не чорні коробки, які час від часу випускають правильні, схожі на шибениці.
Будівля пап - це не висміювання, це не майбутнє бачення, це не якесь концептуальне мистецтво, яке я збив, щоб отримати фінансування.
Це перша реалізація про те, як комп'ютерні системи будуть змушені працювати, коли вони виростуть і отримають відповідні робочі місця.
Це не обіцяє майбутнє, а показує, що існує. прямо сейчас...дисципліна, аудиторія, оцінка придатності, еволюціонування.
Все це, робота, сьогодні, у виробництві, не ламаючи речі (в основному).
Для заучок у залі (привіт, колеги-ботани), ось як створюється інструмент:
sequenceDiagram
participant U as User Intent
participant P as Planner
participant C as Contract Generator
participant G as Code Generator
participant T as Test Generator
participant E as Evaluator
participant M as Memory
U->>P: "I need a tool that flags violations"
P->>P: Generate execution plan
P->>C: Plan details
C->>C: Define interface.json
C->>G: Contract + Plan
G->>G: Generate main.py
G->>T: Code + Contract
T->>T: Generate tests
T->>E: All artifacts
E->>E: Run test suite
alt Tests Pass
E->>M: Store in procedural memory
M-->>U: Tool ready for use
else Tests Fail
E->>G: Feedback for improvement
G->>G: Regenerate with context
G->>T: Updated code
T->>E: Retry validation
end
Кожна невдача - це не таємниця, а нагода вчитися.
Якщо вам потрібні всі технічні подробиці, перегляньте серію семантичних розвідок:
Це доказ концепції. База будується. Підхід підтверджено. Діаграми необов' язкові.
Я не інженер ШІ і не програміст Python. Я - людина, яка мала ідею і використовувала Code Клода, щоб створити її.
Код існує, він працює. відкритий код GitHub (Будь ласка, не крадьте його, просто користуйтеся ним належним чином).
Далі це перетворюється на продукт, який можуть використовувати організації, щоб побудувати системи штучного інтелекту, які працюють на шкалі, відповідно до дисципліни, підзвітності та надійності, які вимагає промислове програмне забезпечення (і що ваш генеральний директор обіцяв Раді).
Я провів останні роки. [Якщо хтось, хто не має досвіду Python може створити це за допомогою ШІ, уявіть, що справжні інженери можуть зробити з цією концепцією.
Якщо ви зацікавлені в тому, щоб зробити це ♫ Ви хочете використовувати його, інвестувати в нього, або просто купити мені достатньо кави, щоб закінчити її будівництво.
Контакт: scott. halloway+dse@ gmail. com
ШІ не обов'язково має бути крихким, непереконливим, і незв'язаним. З правильною дисципліною від початку_початки, контрактів, специфікацій, і т. д.Ай може стати справжнім програмним забезпеченням.
Програмне забезпечення, яким ви можете довіряти. Програмне забезпечення можна покращити. Програмне забезпечення можна перевозити без перетину ваших пальців.
І на відміну від більшості тонів, це вже працює.
Хто купує перший раунд?
© 2026 Scott Galloway — Unlicense — All content and source code on this site is free to use, copy, modify, and sell.
